





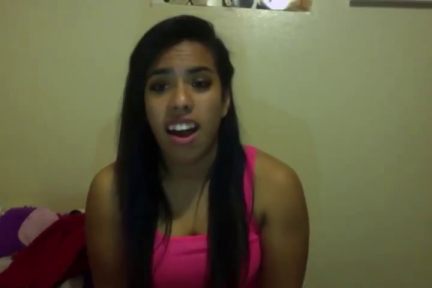




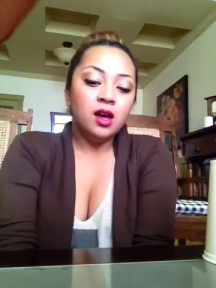

















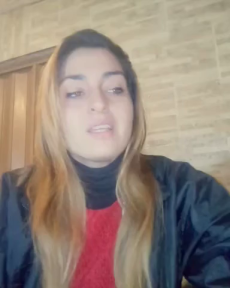




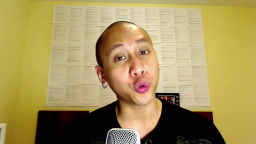

































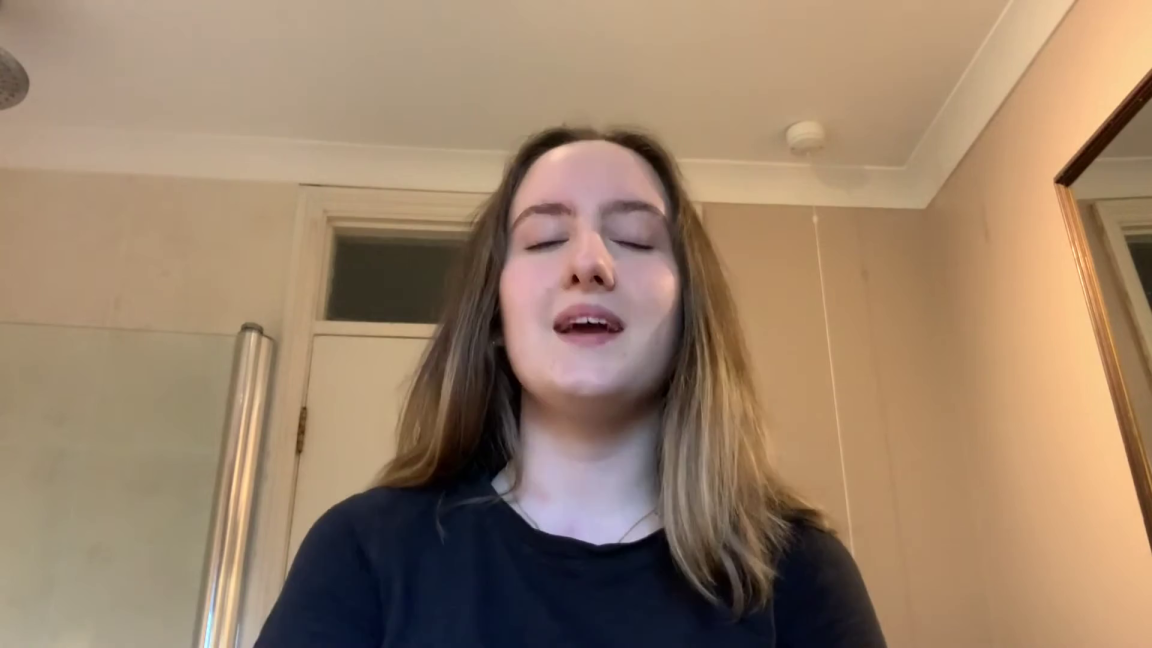






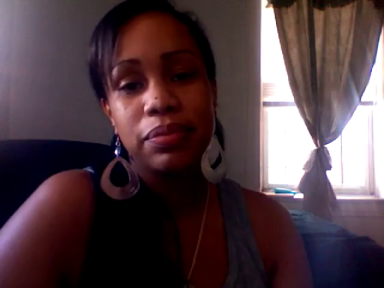
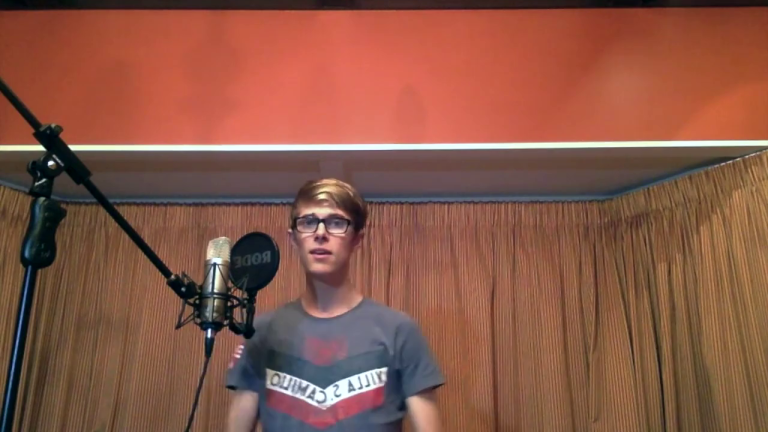
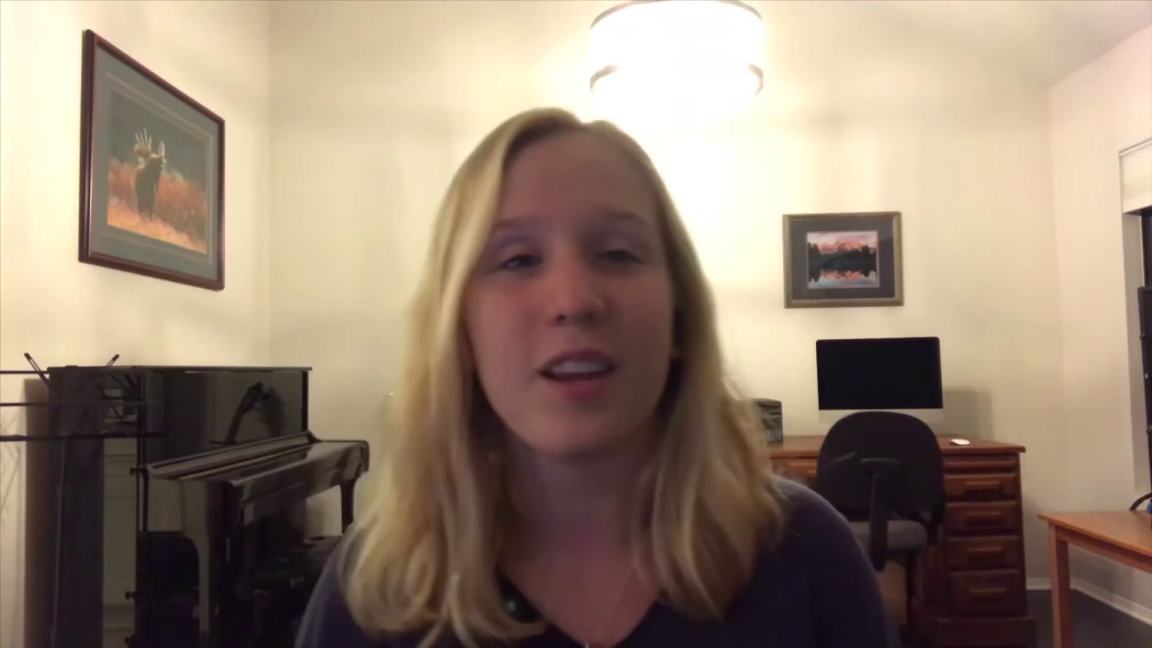
Acappella comprises of around 46 hours
of a cappella solo singing videos sourced from YouTube,
sampled across different singers and languages.
These YouTube videos were all publicly available at the time of the dataset creation.
The idea behind Acappella is to provide a large-scale dataset
to train audio-visual models for singing voice separation.
Each video recording has been manually selected to exclude parts
of the videos that do not satisfy any of the following characteristics:
single frontal face view without occlusions, minimal background
noise, no beatboxing, no snapping fingers, songs with lyrics
(e.g. we avoid humming and yodelling).
The dataset comprises of 1493 different video samples in total spanning four language categories:
English, Spanish, Hindi and Others.
As a part of the dataset, we also provide the splits for the training
set, validation set and test set. The training set makes up around
80% of the total dataset. Around 7% of the dataset forms the
validation set which is used during the training to save the best
checkpoint. The test set is divided into the following subsets:
seen-heard and unseen-unheard. The seen-heard test subset consists of samples from known
singers, i.e. singers seen in the training set.
The unseen-unheard test subset contains singers who are not a part of the training set.
The unseen-unheard test subset also contains samples from languages not seen
in the training set. It presents an approximately
uniform distribution of samples across language categories and
gender. The dataset statistics are shown in the figures below.
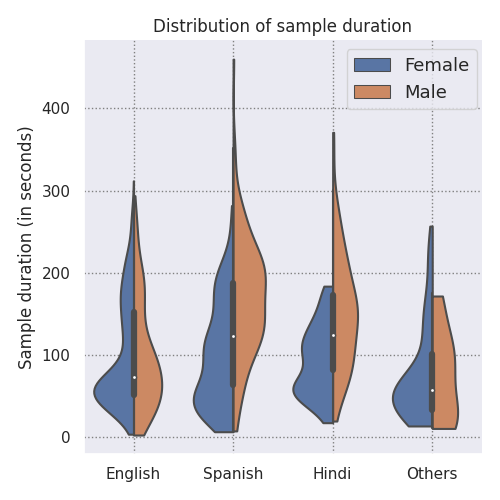
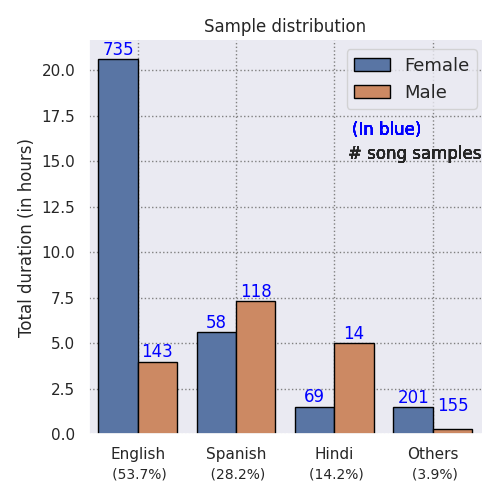
Note that the Acappella dataset is unbalanced in terms of the duration as it contains more
female samples than the male ones. This unbalance is present in the training set, validation
set and the seen-heard test subset. However, the unseen-unheard test subset is balanced with
respect to the gender as well as the language categories. The languages included in the ‘others’
language category in the training set are: Italian, Portuguese, Indonesian, Kannada, Arabic,
and Turkish. The samples from ‘others’ language category belonging to the unseen-unheard
test subset are totally new in the sense that these languages were not included in the training
set, those are: Greek, Persian, Assamese, Tamil, Malayalam, Ukrainian, and Croatian.
How to use?
To use the dataset, we recommend the users to install the pip package
acappella_info that contains
all the necessary info related to the dataset. Alternatively,
we also provide the files below for the convenience of viewing.
The IDs of all the YouTube videos that belong to the Acappella dataset are made available. Each row in the above csv files corresponds to a sample in the dataset. As one can see in the splits.json file, a sample is identified in the format: ID_start_timestamp_to_end_timestamp. Each sample is a trimmed segment of a full-length video obtained by trimming that full-length video along the start timestamp and end timestamp. This way we exclude parts of the full-length videos that are not particularly useful to our task for our experiment setup (e.g. concealed lips, background noise). The start and end timestamps are provided for each of the video IDs (see the csv files). We also provide information regarding the language of the song, the gender of the singer and the duration of each sample. The pip package provides get methods to access all this information.
Traces
For this specific paper, we considered certain 4 second segments from the samples for validation and evaluation on the test sets rather than evaluating on the full-length samples (note that a sample is a trimmed excerpt obtained from a full-length video). The 4 second segments were obtained randomly, but frozen across different models for the sake of fair comparison of their performances.
NOTE: It is likely that some videos from the dataset might not be available in future if the users takes them down from YouTube or if the users make their videos private or if country-specific restrictions are applied on the videos.
LICENSE
The Acappella dataset is available to download for
commercial/research purposes under a
Creative Commons Attribution 4.0 International License.
The copyright remains with the original owners of the videos
listed in the dataset.
Click here for the complete version of the license.
Caution: We note that the distribution of identities in the
Acappella datasets may not be representative of the
global human population. Please be careful of unintended
societal, gender, racial and other biases when training or
deploying models trained on this data.
Note: These license terms have been inspired from
that of the
VoxCeleb dataset.