Audio Encoder
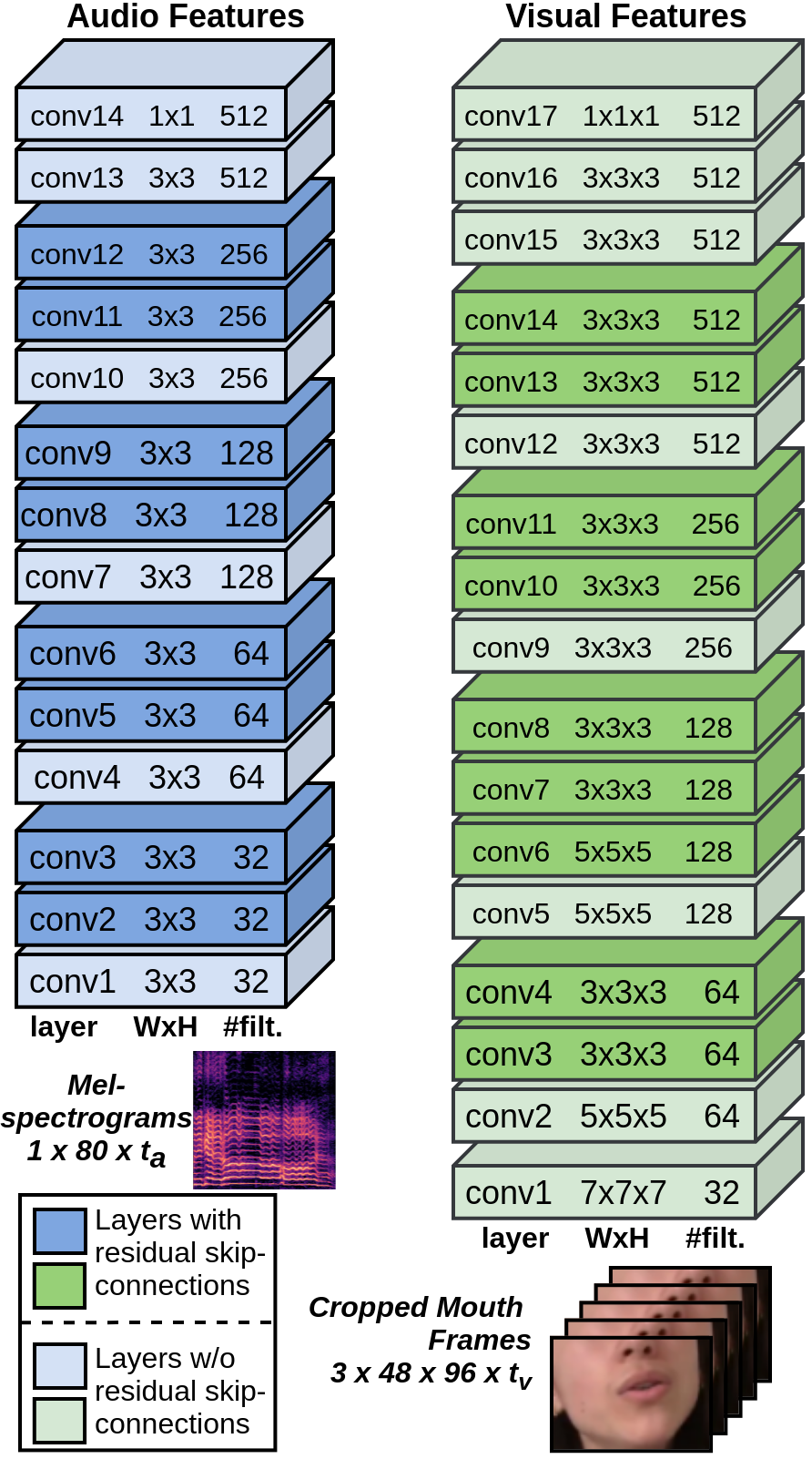
Visual Encoder
Synchronisation Block
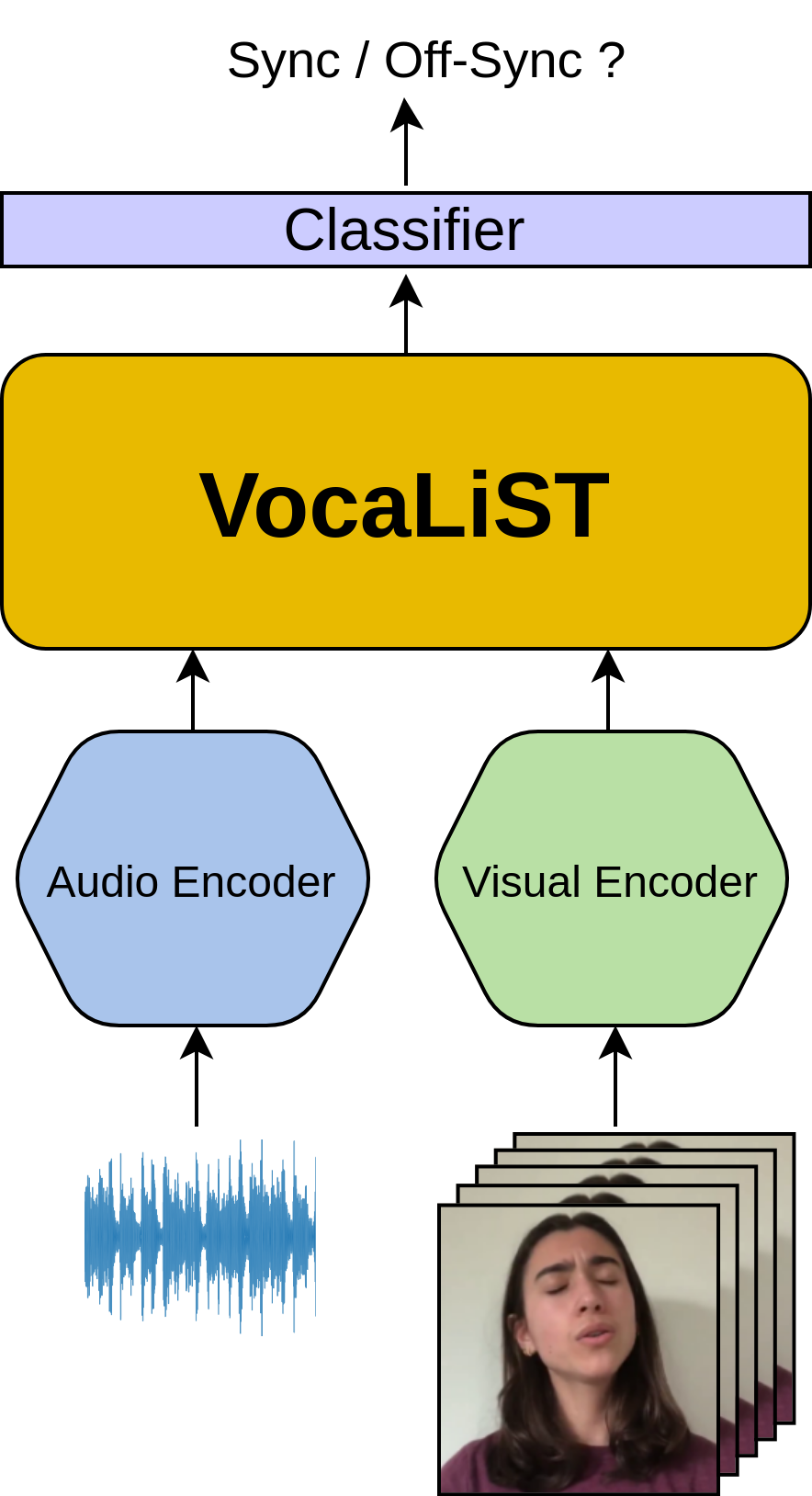
We design a powerful cross-modal audio-visual transformer that can use the audio-visual representations learned in its cross-modal attention modules to deduce the inherent audio-visual correspondence in a synchronised voice and lips motion pair. We refer to our transformer model as VocaLiST, the Vocal Lip Sync Transformer. Its design is inspired by the cross-modal transformer from [2]. The cross-modal attention blocks track correlations between signals across modalities.
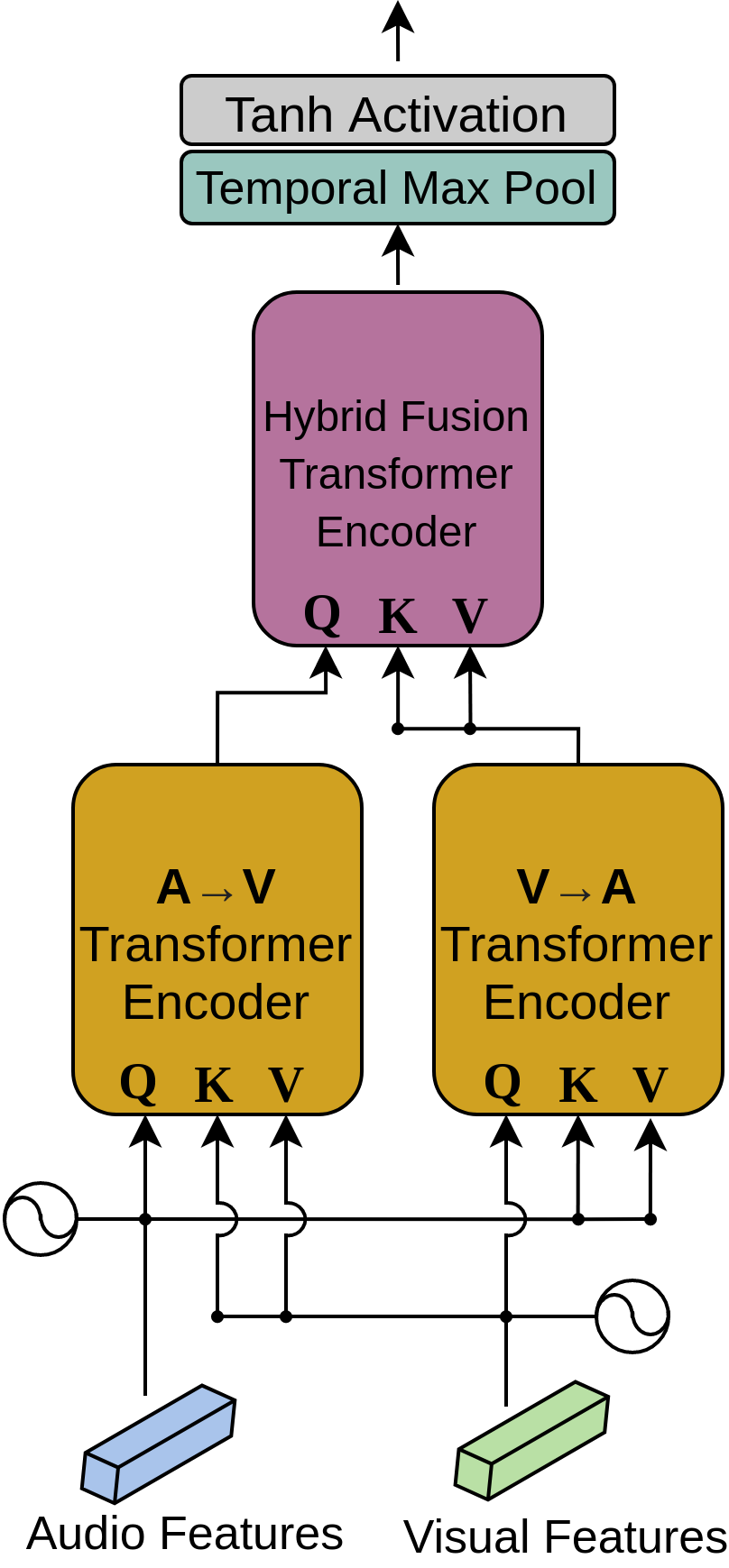
The synchronisation block contains three cross-modal transformer encoders, each made up of 4 layers, 8 attention heads and the hidden unit dimension of 512. The A→V unit takes in audio features as the query and the visual features as the key and values. The roles of these audio and visual features is swapped in the V→A unit. The output of the A→V unit forms the query to the hybrid fusion transformer unit, while its key and values are sourced from the output of the V→A unit. We max-pool the output of this hybrid fusion unit along the temporal dimension and pass it through tanh activation. Fig. 1 shows the architecture of VocaLiST.
Finally, there is a fully-connected layer acting as a classifier which outputs a score indicating if the voice and lips motion are synchronised or not. The whole architecture can handle any length of audio and visual inputs.
References
[1] K. Prajwal, R. Mukhopadhyay, V. P. Namboodiri, and C. Jawahar,
“A lip sync expert is all you need for speech to lip generation in the
wild,” in Proceedings of the 28th ACM International Conference
on Multimedia, 2020, pp. 484–492.
[2] Y.-H. H. Tsai, S. Bai, P. P. Liang, J. Z. Kolter, L.-P. Morency, and
R. Salakhutdinov, “Multimodal transformer for unaligned multimodal
language sequences,” in Proceedings of the conference.
Association for Computational Linguistics. Meeting, vol. 2019.
NIH Public Access, 2019, p. 6558.