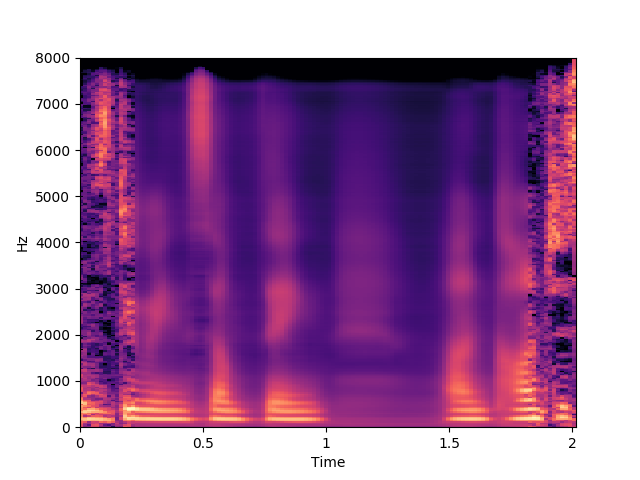
Synthesized speech: 1600 ms
Speaker 30: brip5p
GT
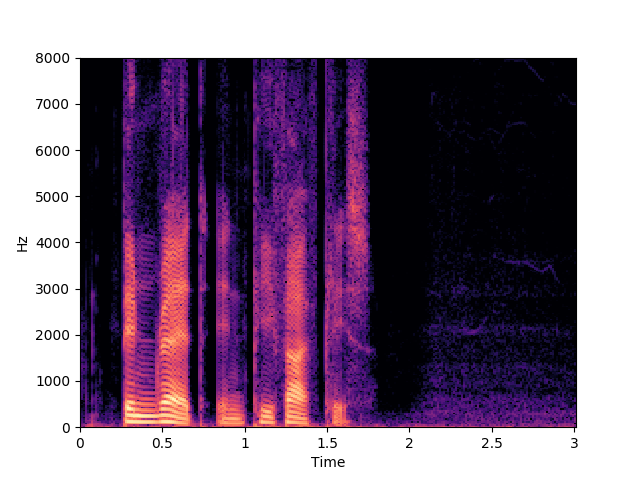
Corrupted Input
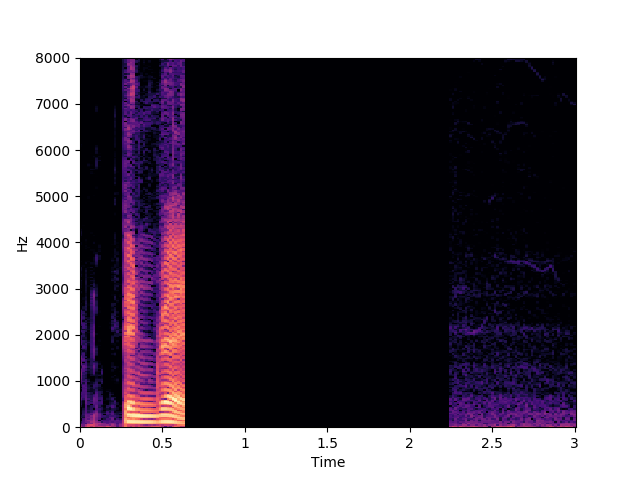
Morrone et al. [1]
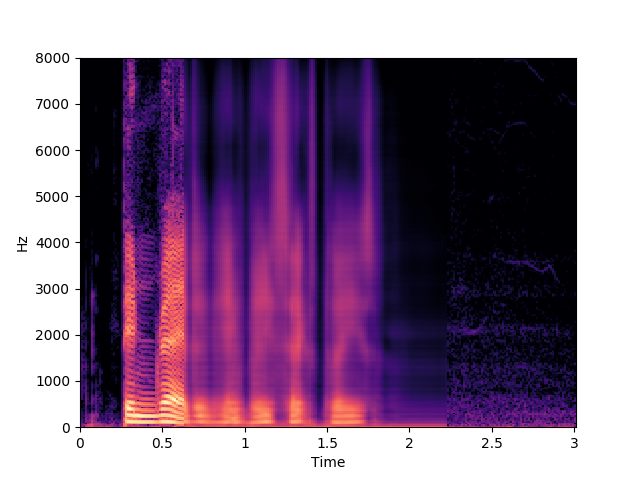
Ours, audio-visual
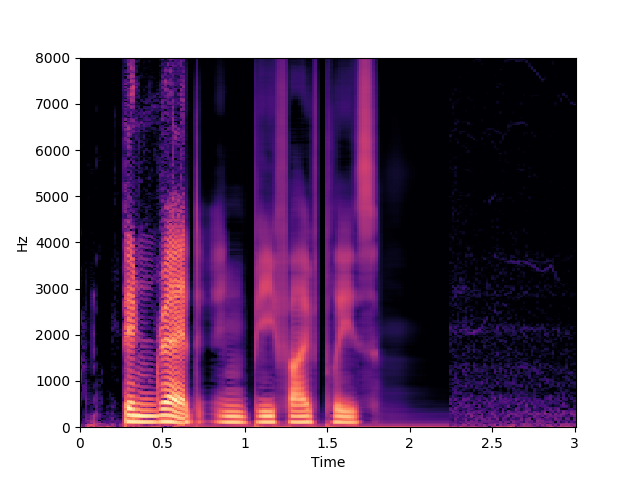
Ours, audio-only
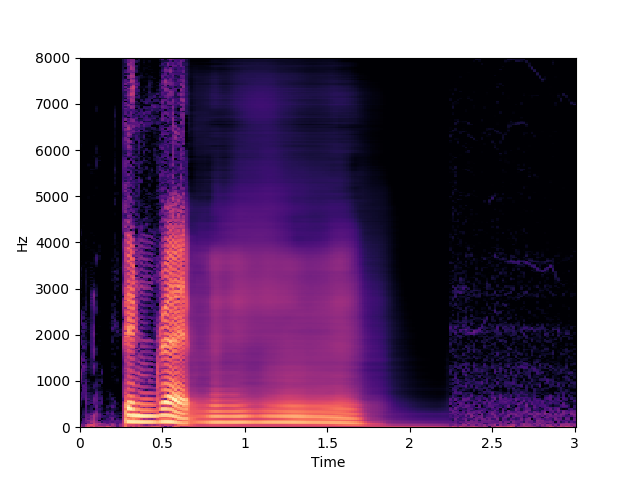
Speaker 30: bgbr5p
GT
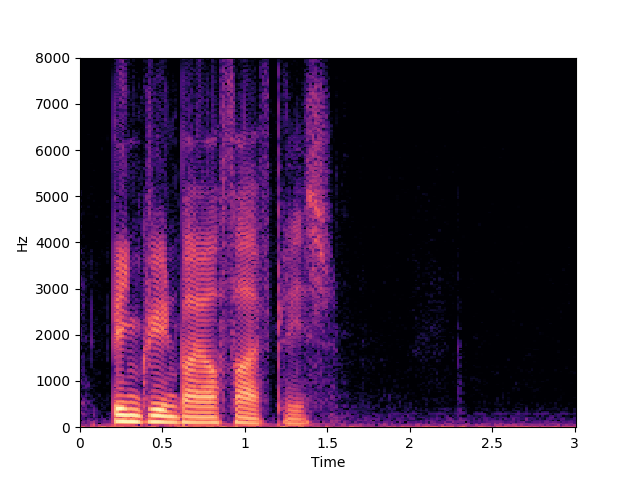
Corrupted Input
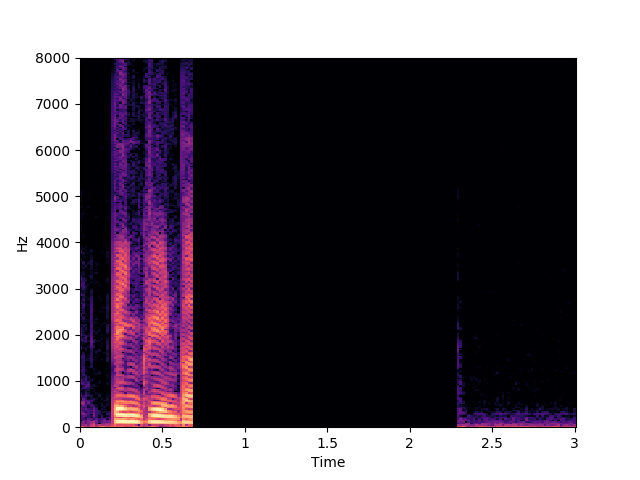
Morrone et al. [1]
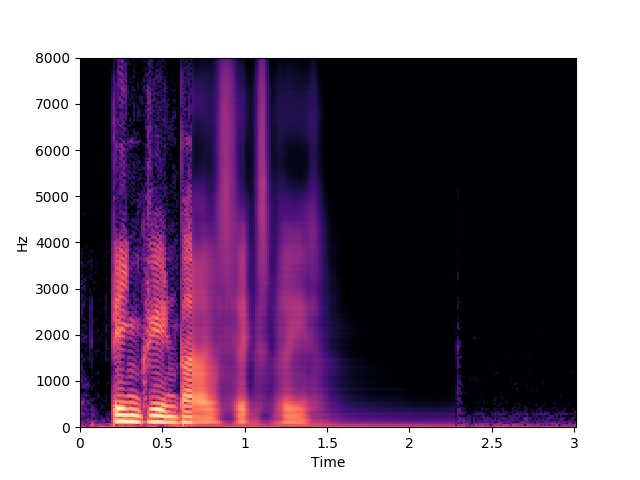
Ours, audio-visual

Ours, audio-only
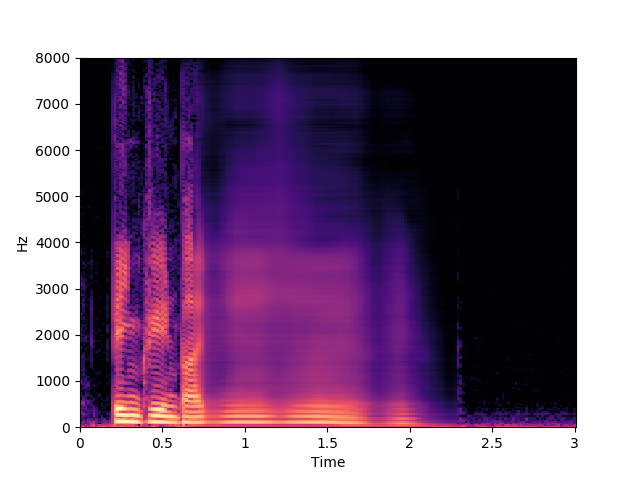
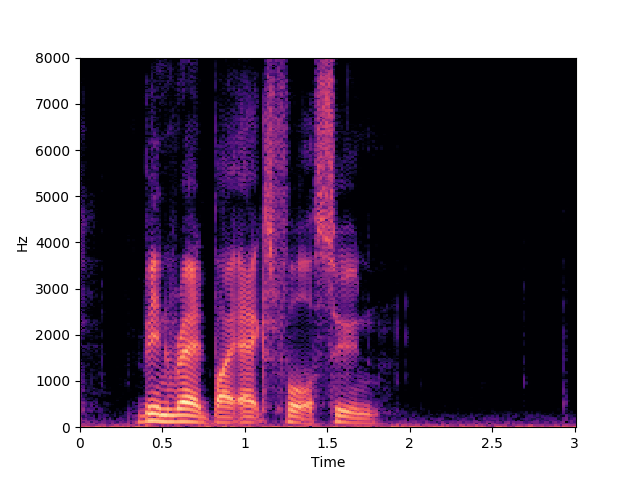
Speaker 32: brbx4s
GT
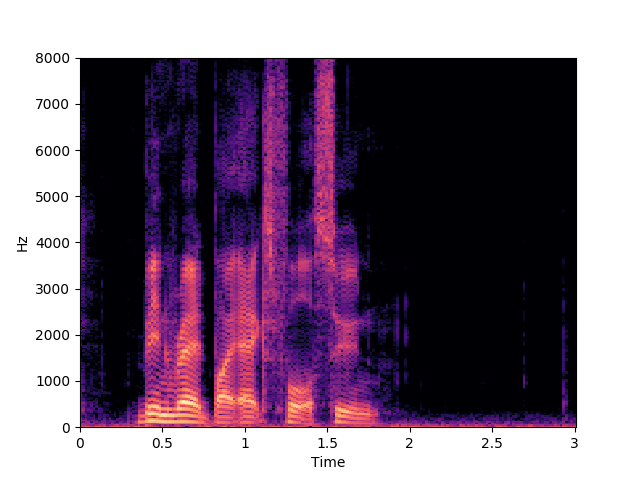
Corrupted Input
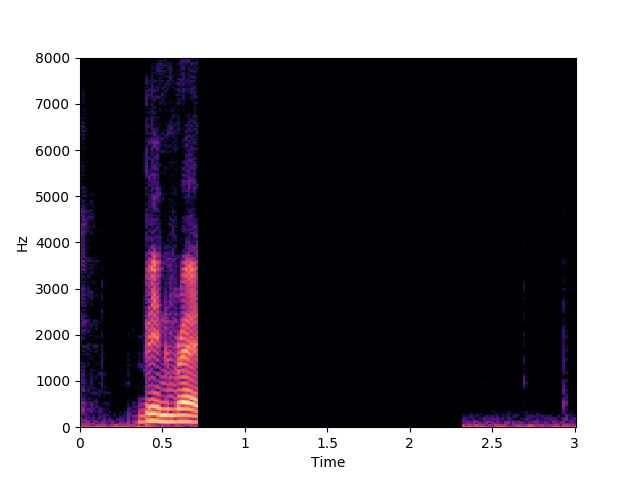
Morrone et al. [1]
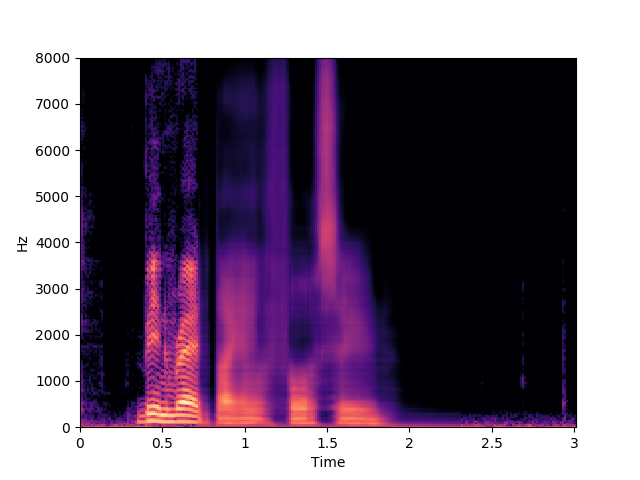
Ours, audio-visual
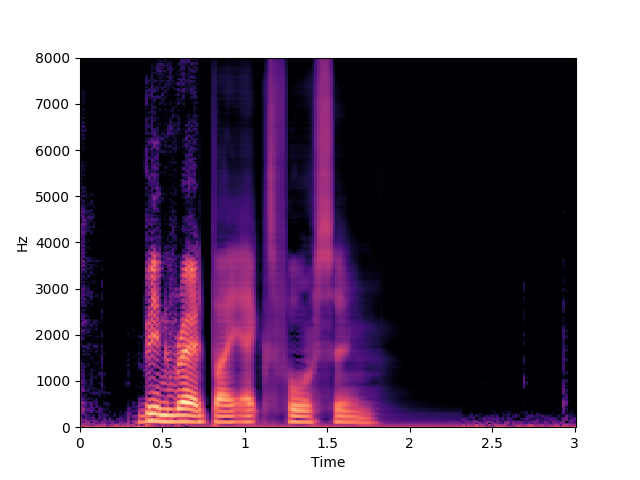
Ours, audio-only
In this example we can see that Morrone's model predicts "been red by l four soon", while our proposed model predicts "been red by x four soon". This shows the ambiguity between some visemes and the corresponding phonemes described in the limitations section of the paper.
Synthesized speech: 800 ms
Speaker 32: brbx4s
GT
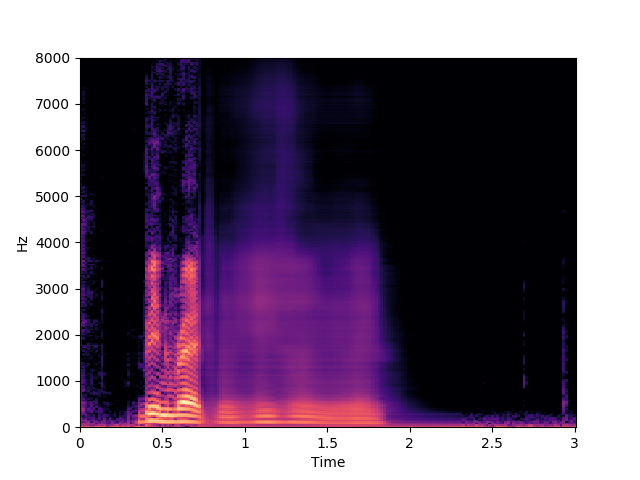
Corrupted Input
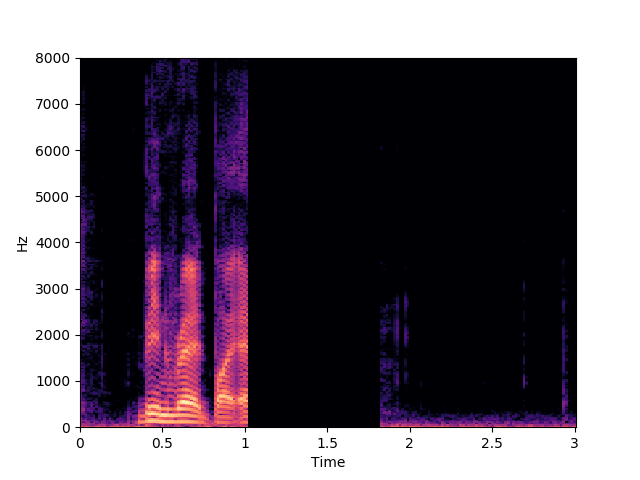
Morrone et al. [1]
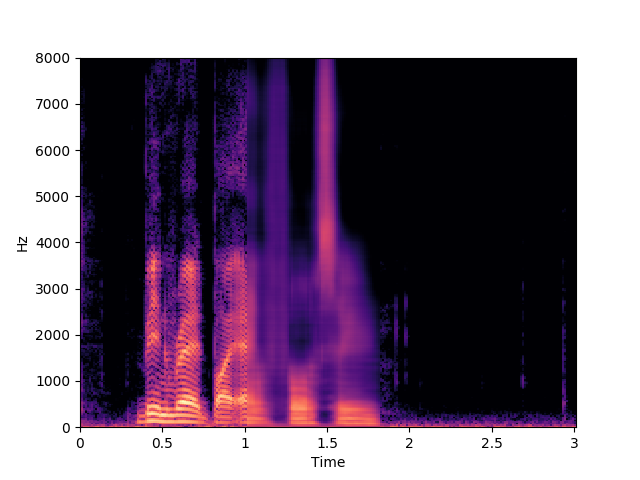
Ours, audio-visual

Ours, audio-only
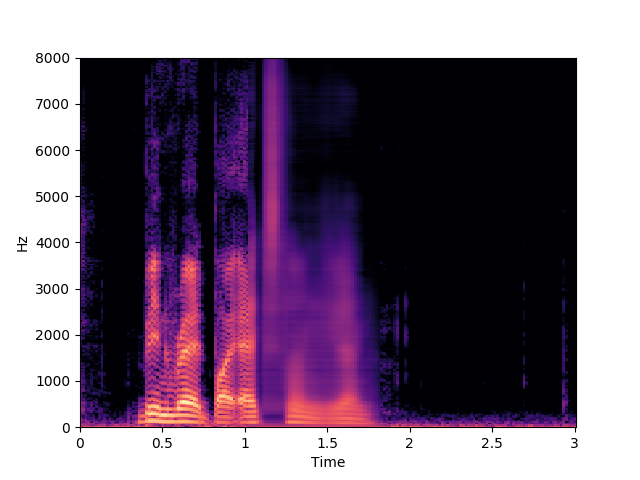
In this example, we can observate how the audio-only baseline is attempting to inpaint the corrupted segment with a sentece learned from the dataset.
Speaker 30: pwwb1n
GT
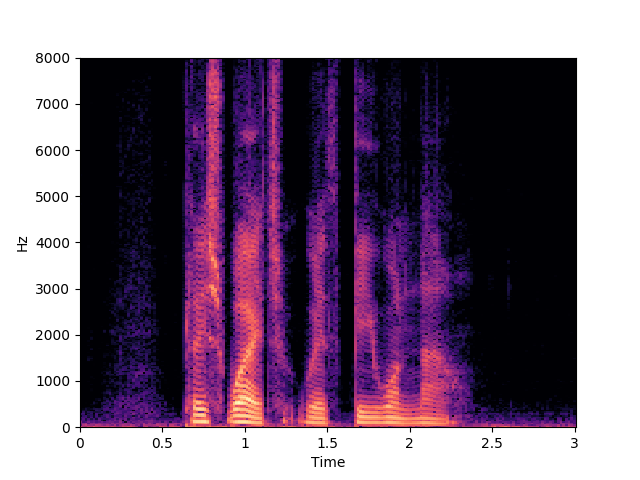
Corrupted Input
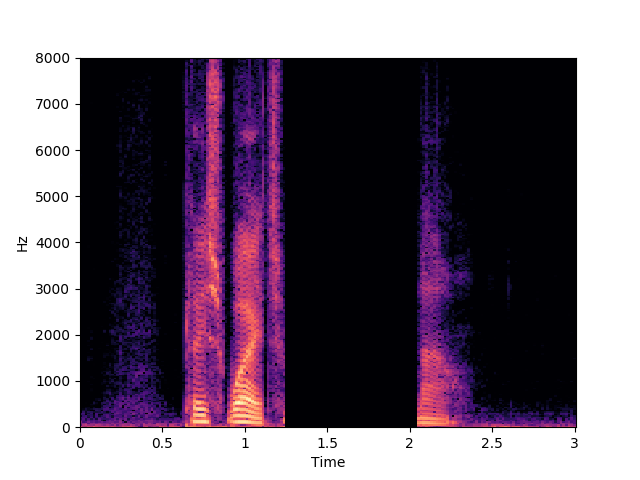
Morrone et al. [1]
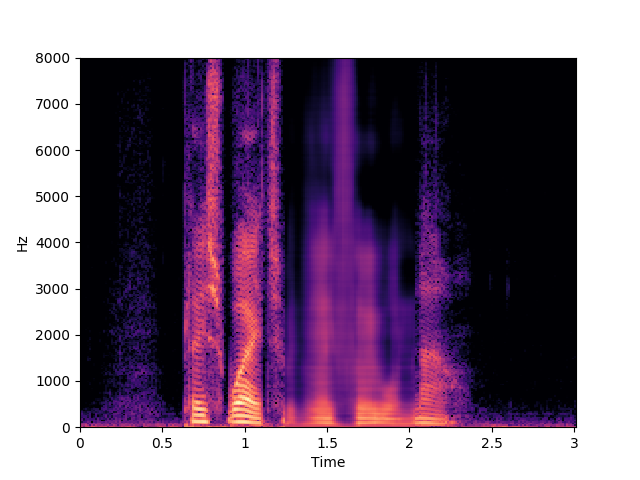
Ours, audio-visual
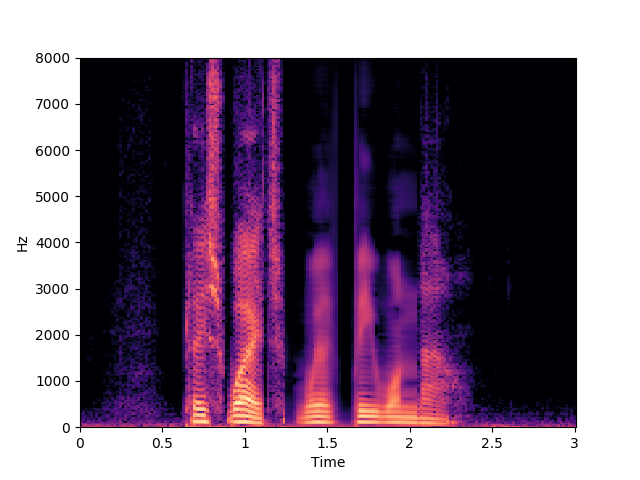
Ours, audio-only
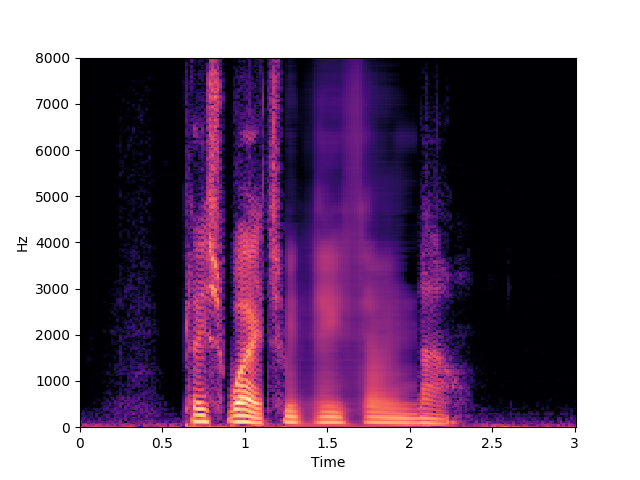
Synthesized speech: 400 ms
Speaker 32: lgii6a
GT
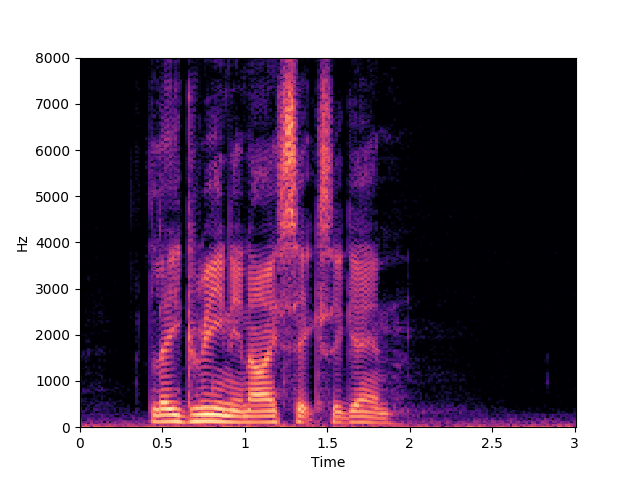
Corrupted Input
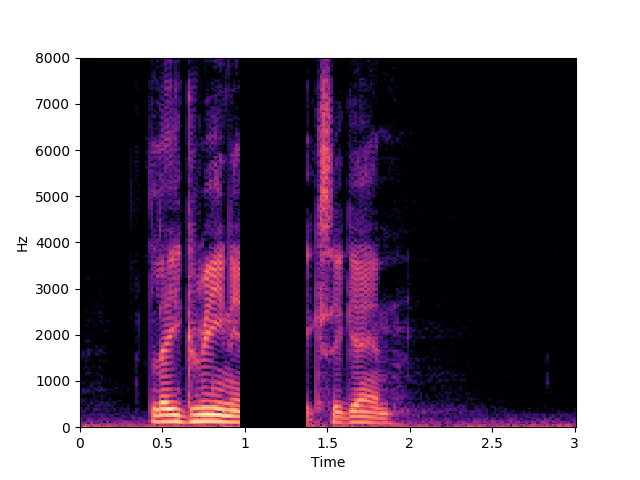
Morrone et al. [1]
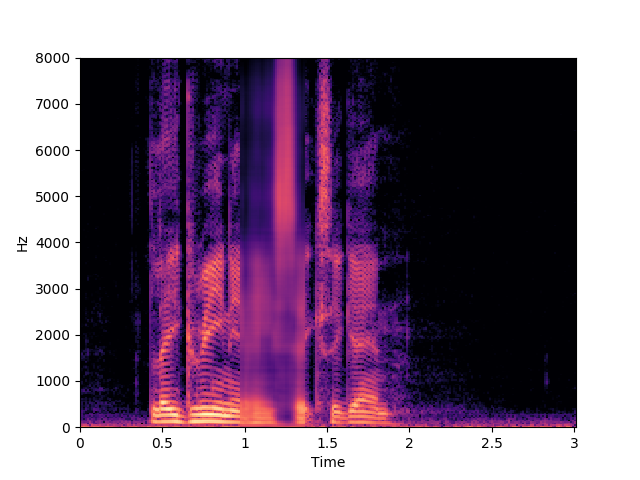
Ours, audio-visual
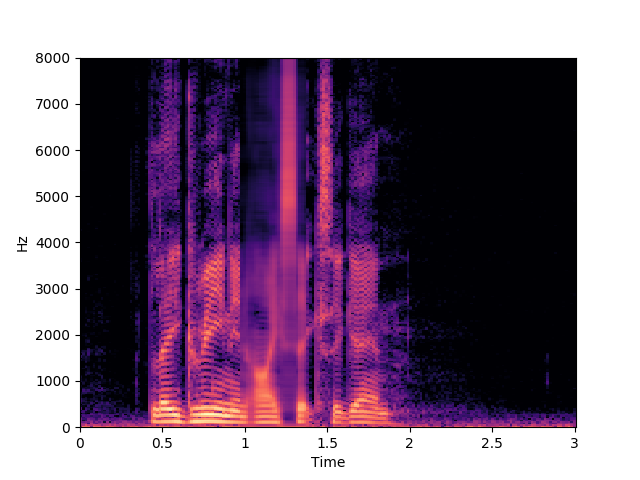
Ours, audio-only

Synthesized speech: 160 ms
Speaker 34: swie4s
GT
Corrupted Input
Morrone et al. [1]
Ours, audio-visual
Ours, audio-only
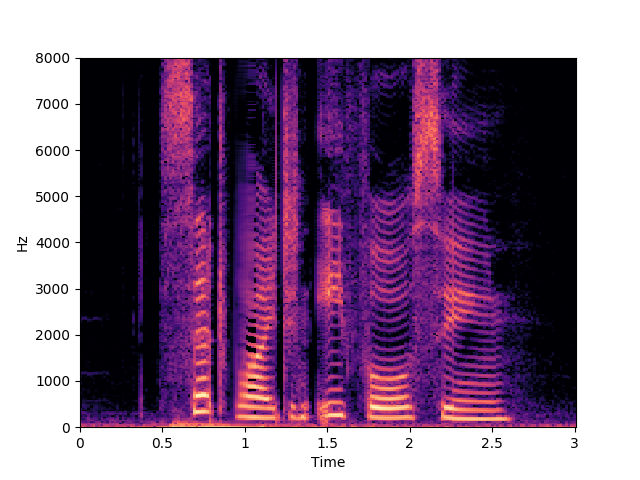
Voxceleb unseen-unheard: 1600 ms
GT
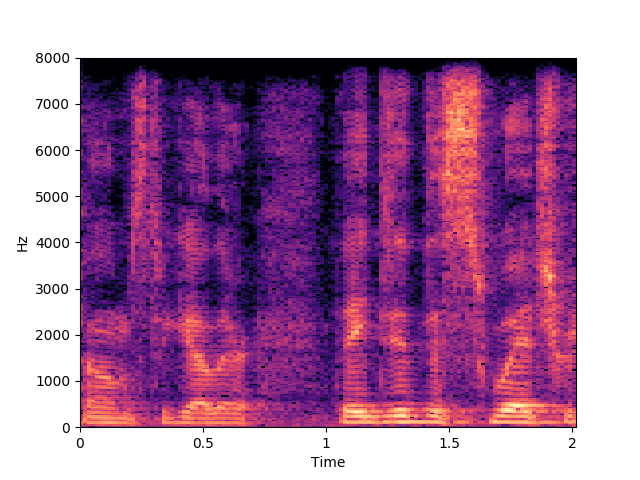
Corrupted Input
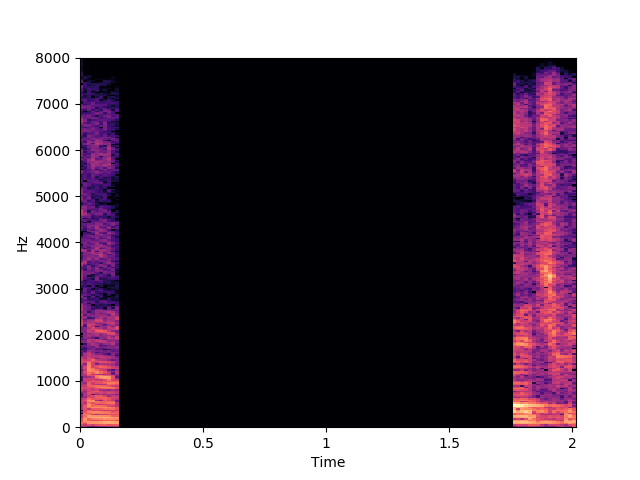
Ours, audio-visual
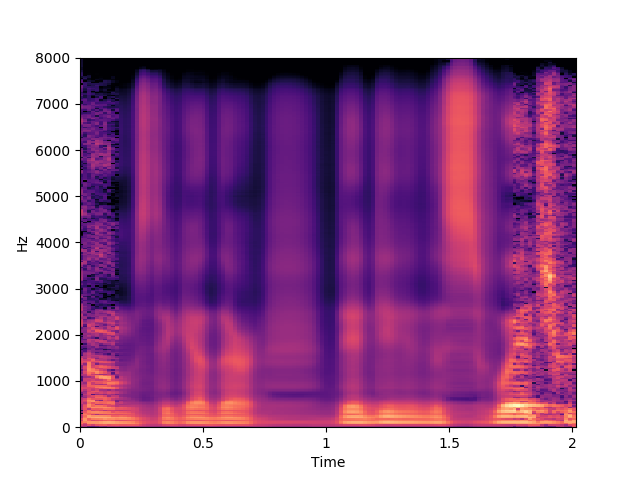
GT
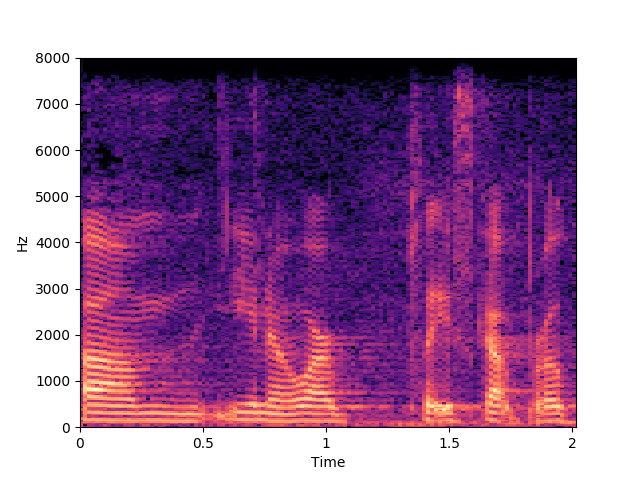
Corrupted Input
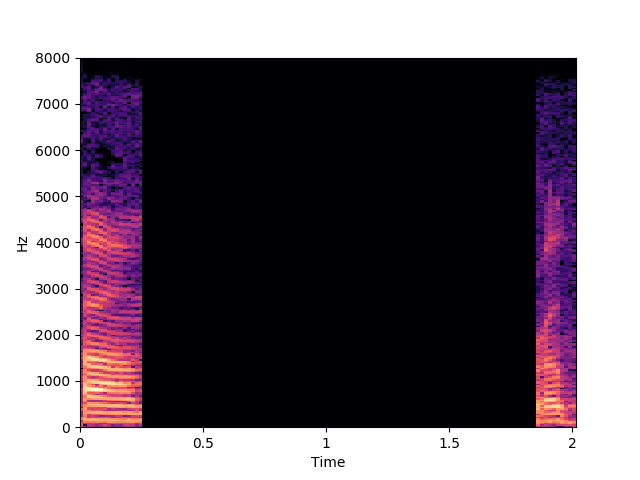
Ours, audio-visual

GT
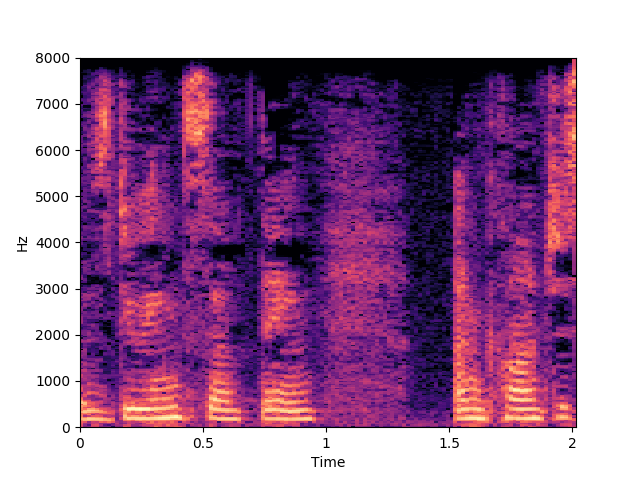
Corrupted Input
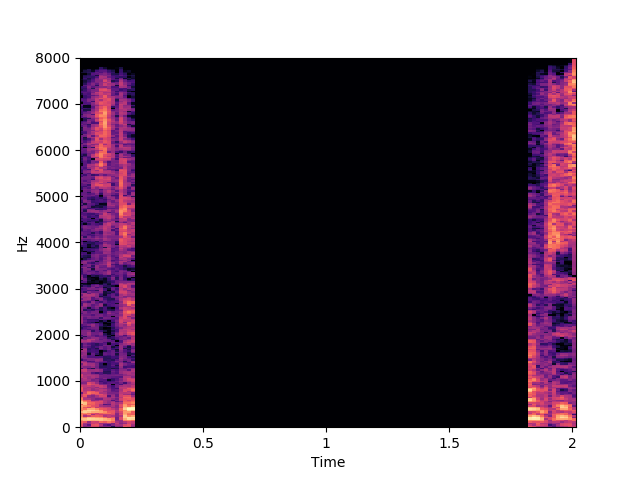
Ours, audio-visual